The Explosion of Telemetry Data: A Blessing or a Curse for Developers?


Imagine having just made the decision of running through a full battery of medical tests. Maybe it’s your annual physical, or you just hit 45 and want a deeper understanding of your physical health; but for whatever reason, you want to know. You need to know. You make your way to the clinic, and you’re there for half a day, and you undergo a number of different tests and evaluations - full blood panel, urine, EKG, vo2 max, blood pressure, and more. You wrap up, and wait in the waiting area for your results. Finally someone in scrubs approaches you with a thick manila folder, full of documents - numbers, metrics, scans and images, and more - and says to you, “Everything you need to know is here. Good luck!” You’re left dumbfounded, wondering what we would all be wondering: “Wait, I need a medical specialist to interpret this data for me!”
This is effectively the state of observability today. There has been an explosion of telemetry data since the advent of public cloud. Dynatrace’s recent “State of Observability 2024” report surveyed 1300 CIOs, and 86% of them agreed that cloud-native technology stacks have produced an overwhelming amount of telemetry data. Other large observability players have published near-identical primary research on this topic. This leaves enterprise developers in a lurch. Much like the patient described above, developers are left to manually and tediously correlate and interpret vast amounts of telemetry data, pieces of which when combined, will tell a story, but getting there has become infinitely challenging. There are effectively two major use cases for which telemetry data is essential: 1/ Fixing an incident, restoring systems to health; and 2/ Optimizing your systems (to help prevent future incidents).
We were happy to see Sapphire Ventures recently articulate a strong opinion on the rapidly shifting observability landscape, especially when it comes to how LLMs could upend the longstanding lucrative space. Reading through their article, it is clear that they thoughtfully recognize the problem space and the opportunity to disrupt incumbent observability players: MTTRs remain high, while investments in observability tools continue to skyrocket. Clearly, something isn’t adding up. Of course, we were happy to see Flip AI represented in their Observability Market Landscape map, as well as specifically called out as a company and technology trying to solve the problem space articulated above. What they call out about Flip AI is directionally correct:
“LLMs are also making it easier to understand complex system alerts, translating esoteric technical jargon to more human readable sentences. Because LLMs can ingest and analyze large volumes of unstructured data, companies like Flip AI are finding new ways to apply them to more traditional log analytics and AI-Ops capabilities, identifying patterns, inferring meaning (e.g., sentiment analysis of user feedback) and determining root cause across complex systems.”
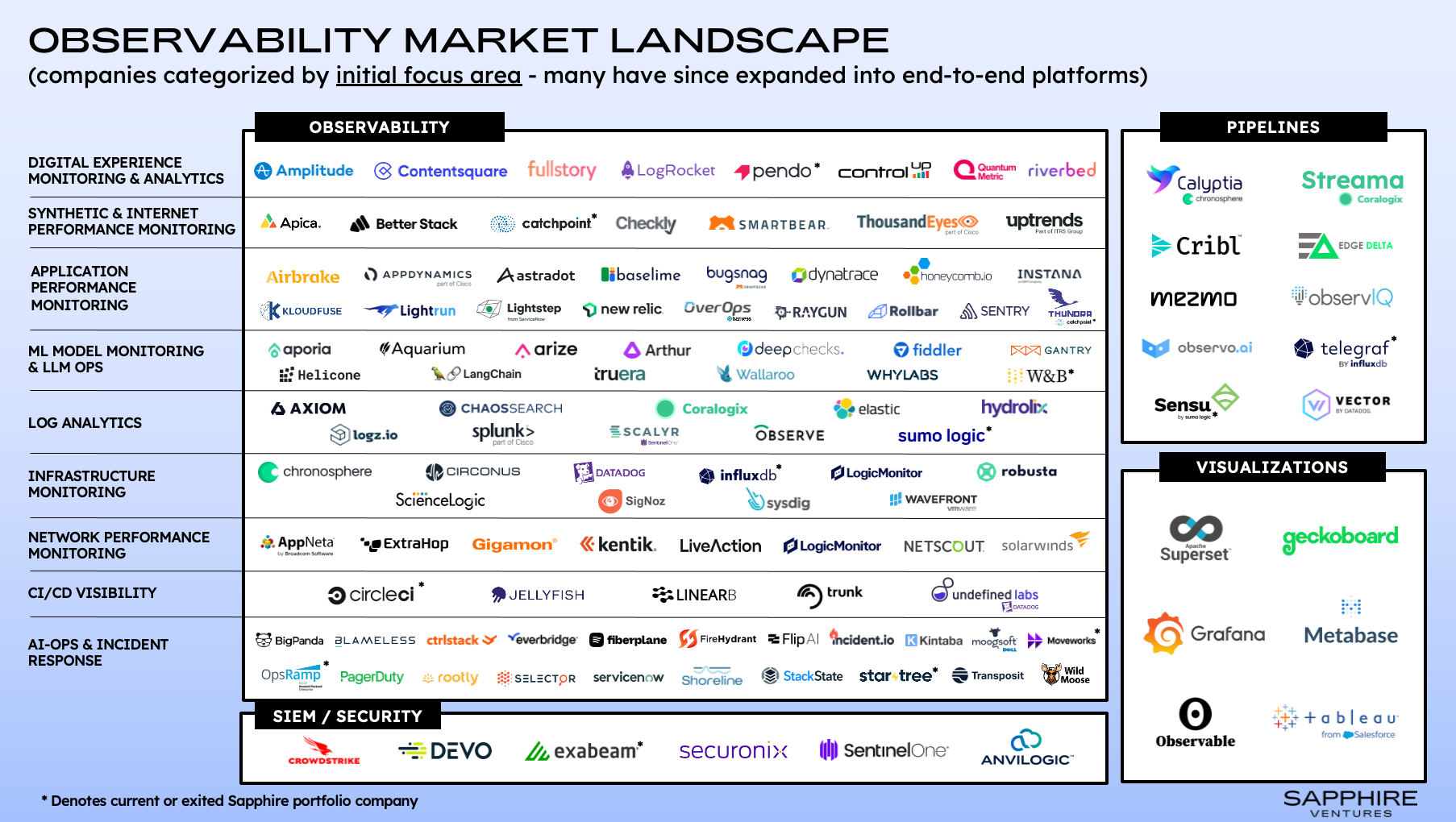
But we would strenuously add that Flip AI goes many levels deeper. Today, the imagination around what an LLM can do is largely confined by outputs in English, but with the appropriate expertise, LLMs are capable of so much more. Telemetry data is not only vast, but also incredibly diverse. It spans a number of modalities - logs, which is textual data; metrics, which is time series data; and traces, which we classify as graph data - and across different platforms, such as Splunk, Elastic, Datadog, New Relic, AppDynamics, Prometheus, etc, these modalities can have their own proprietary sub-syntaxes. One of the first jobs that our mixture of experts (MoE) LLM performs is the harmonization of all of this data. While this may seem tactical, nerdy and hard to grasp the magic of, do not be fooled: building LLMs that can dynamically understand, contextualize, smoothen and harmonize large amounts of diverse data is part of the magic of Flip AI. Of course, this becomes a core input into our sophisticated pipeline and workflow, where other parts of our MoE LLM are responsible for interpreting telemetry data as a semantic language, so that it can connect, correlate, and ultimately derive a root cause of an incident using the telemetry data available to it within the context of a specific incident or anomaly. This is what truly WOWS our customers when we show them.
This leads us to discuss another very important observation from the Sapphire article: the architectural shift they reference as “Bring Your Own Storage.” The authors say, “By eliminating proprietary (and cost-prohibitive) indexers, this approach also unlocks optionality at the storage layer.” We agree, and see this trend in some of our largest customers. In fact, when customers learn about the ability for Flip AI to agnostically interpret observability data no matter its modality, structure, state or data store, it can accelerate the shift to “BYOS:” Customers can pick and choose “cheap and deep” data stores for their logs, metrics or traces, like Amazon S3, and use an AI layer like Flip AI to help them make sense of the data when either triaging an incident or pursuing infrastructure and application optimizations.
There is no question that the appropriate application of LLMs can and will be highly disruptive and transformative in the observability space, and Sapphire Ventures is right for calling this out. A few years from now, we will look back and think about how crazy it was that we would take that file from the nurse and be totally okay with figuring out what was wrong with our health on our own; that as developers, we’ve been okay looking at endless streams of logs in one system, trying to eyeball dozens of charts and flame graphs in another dashboard, all while being responsive in a Slack war room with a dozen or so domain experts across the stack (i.e. DBAs, networking admins, application engineers, etc). To further spark your curiosity, you need only ask yourself this: “If it were possible to sum up all the technical expertise needed around debugging incidents, and if that group of experts could automatically root cause incidents for me, would that drastically improve my ability to do my job?” It’s not a rhetorical question, go ahead answer it. And when you have, get in touch with us to learn about how we’ve helped answer this question for a number of happy customers.
Read next


Ready to See What Flip Can Do?
